Merge Hangover
I’ve been running my own Ethereum validator since the Beacon Chain’s genesis, on December 1st, 2020.
22 months later, on September 15th, 2022, at block #15537393, the main proof-of-work chain merged with the Beacon Chain, transitioning Ethereum to Proof-of-Stake fully.
The world celebrated a 99.95% drop in Ethereum’s energy consumption and no downtime during this upgrade. Meanwhile my validator started to miss all attestations and get penalized for it:
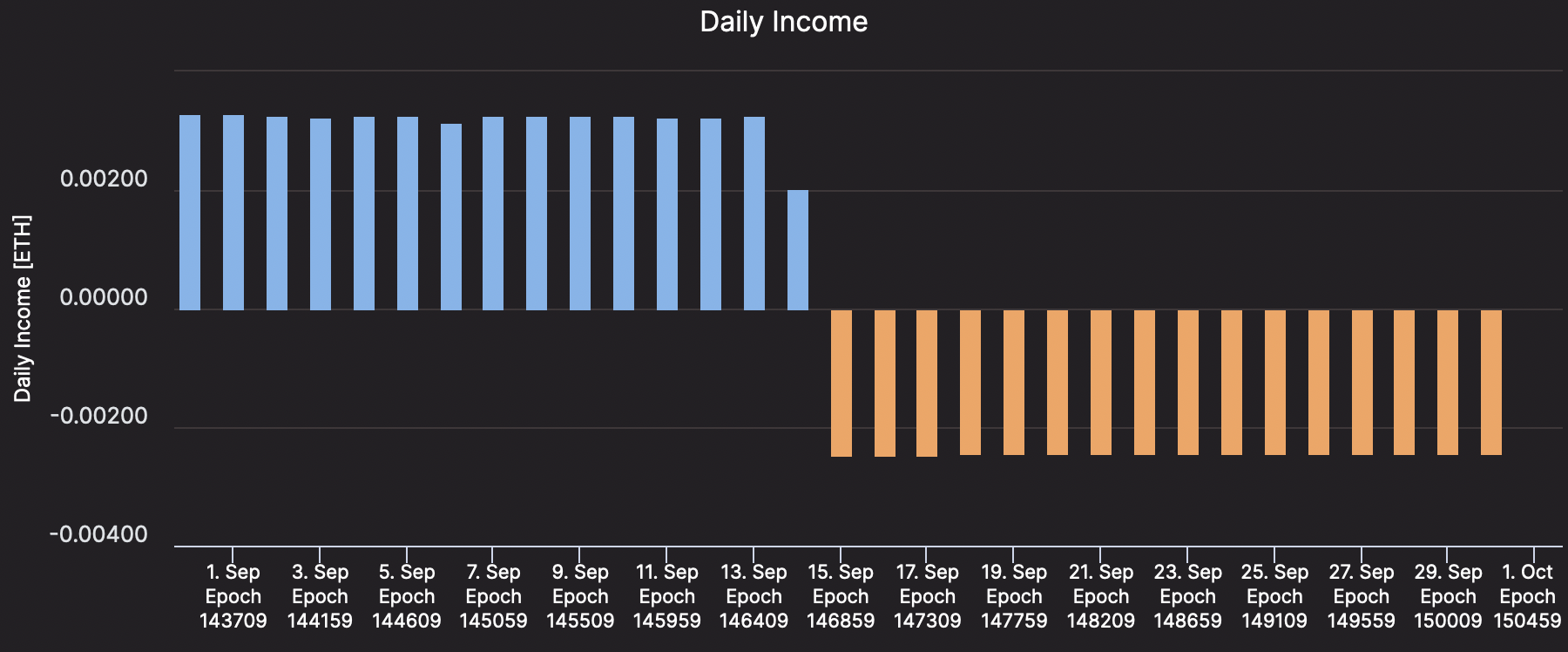
Time to panic.
What broke?
Looking back, I should’ve seen this coming. I was running my validator and beacon node on a hosted VPS, and using Infura to get access to a synced Ethereum node. This was fine before the Merge because the beacon node only needed to talk to Infura every once in a while to detect contract deposits.
When The Merge happened, this stopped working. Validators have to assume the duties of former proof-of-work miners. After the merge, validators propose blocks containing user transactions. In order to do this, a Beacon node (also called “Consensus Layer”, or CL for short) and an Ethereum node (also called “Execution Layer”, or EL for short) collaborate in a tight loop:
- EL needs CL to know which block is coming next
- CL needs EL to gather information about balances, accounts, and transactions
Hence why Infura or other SaaS providers can’t assume that responsibility. The Engine API couples CL and EL clients 1-to-1, introducing a cyclic dependency between them.
Why didn’t I see this coming?
This new requirement (“stakers need to run their own execution client”) went way over my head until the Merge happened. I was (still am!) in the Prysm discord, updating my beacon & validator clients diligently when updates are announced. Before the merge I added a suggested fee recipient to my validator because it caused a warning in logs. But I missed the biggest task and forgot to run my own EL client.
There’s really no excuse, the writing was on the wall:
- Official Ethereum page: “Run both a consensus client and an execution client; third-party endpoints to obtain execution data no longer work since The Merge.”
- Prysm’s guide says “You do need to run an execution client. You can’t use Infura as an execution endpoint provider.”
- Teku’s guide: “Service providers that provide execution layer access, such as Infura, won’t be adequate for a beacon node to continue to function on the network”
- /r/ethstaker: “you will need to run your own execution client”
…I still got caught by surprise, somehow.
VPS? Out of Disk Space
To get back online as quickly as possible I thought about installing and
running an EL client on my existing VPS. Simple. Right? Wrong. My VPS provider
allowed me to purchase a 1TB disk, not more. I tried anyway and predictably ran
out of disk space while syncing. “Predictably”, given geth’s chain data
size is around 1Gb these days.
Geth on EBS? Out of Disk I/O
The next thing I tried: go to AWS and rent an EC2 Ubuntu instance. I picked
m5.xlarge: 16Gb of memory, with a 2TB
EBS
volume attached, and a 10Gb network link. Not bad I thought!
Unfortunately, geth requires fast access to disk, especially during its
initial sync. I learned this the hard way: my node was not syncing, or syncing
very slowly to the point where it’d have taken weeks or months to catch up.
While looking into this problem I came across this github issue, and specifically this comment: “Try erigon, they don’t have these SSD requirements”. Aha! Could it be?
Erigon? Out of Memory
Erigon seemed like a better, less-bloated client: smaller community, tighter codebase, also written in Golang. I had a false start: Erigon, by default, starts up as a full archive node. After a bit of research I found a decent pruning configuration (it’s not that simple):
/home/ubuntu/erigon/build/bin/erigon \
--torrent.download.rate=20mb \
--http \
--http.port 8545 \
--http.api 'eth,web3,net,debug,trace,txpool' \
--authrpc.jwtsecret /home/ubuntu/config/jwt.hex \
--prune=htc \
--prune.h.older=90000 \
--prune.t.older=90000 \
--prune.c.older=90000 \
--private.api.addr=localhost:9090
This worked: my Erigon node did (eventually, after a couple of weeks!) catch up to the chain tip, but required a ton of baby-sitting because of out-of-memory errors. This often meant I had to manually restart my CL and EL clients.
Sep 23 14:09:19 ip-172-31-16-253 systemd[1]: erigon.service: Failed with result 'oom-kill'. Sep 23 14:09:19 ip-172-31-16-253 systemd[1]: erigon.service: Main process exited, code=killed, status=9/KILL Sep 23 14:09:18 ip-172-31-16-253 systemd[1]: erigon.service: A process of this unit has been killed by the OOM killer.
Unfortunately, these OOM errors persisted even after the initial sync. The reliability of this setup was poor: during 3 weeks, on any given day, it was a coin flip on whether I’d make money or lose money:
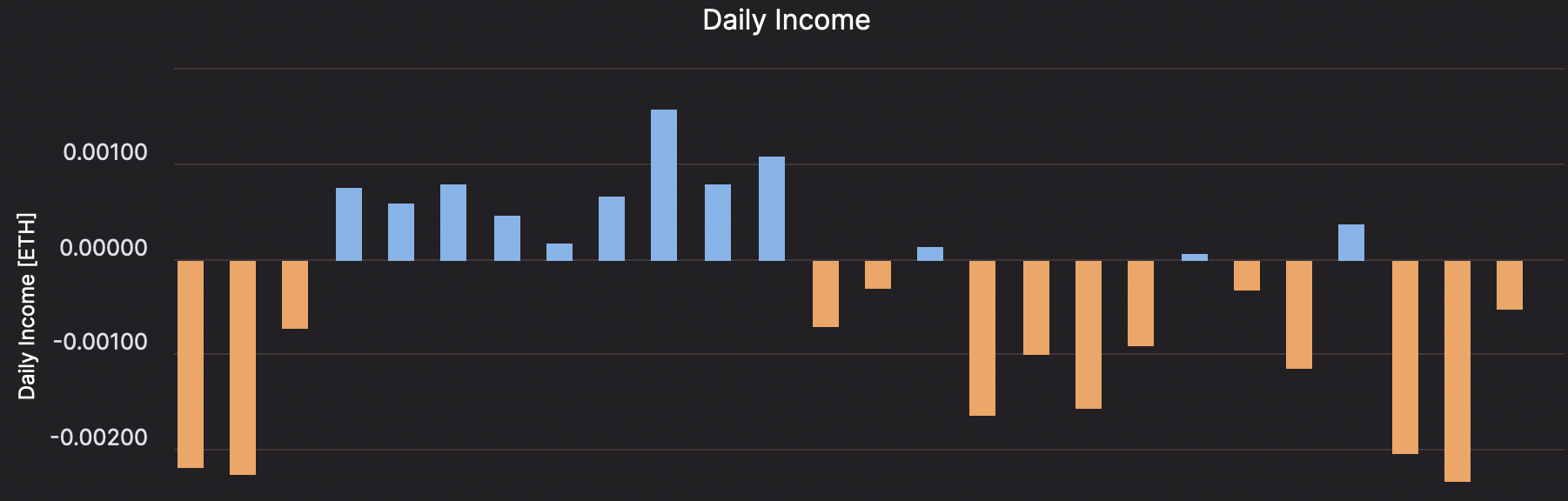
AWS? Out of Money
Outside of reliability issues caused by out-of-memory crashes, I was worried about the price of this AWS setup. Looking at my monthly charges I’d spent ~$300 on EC2 and associated costs (EBS, bandwidth):
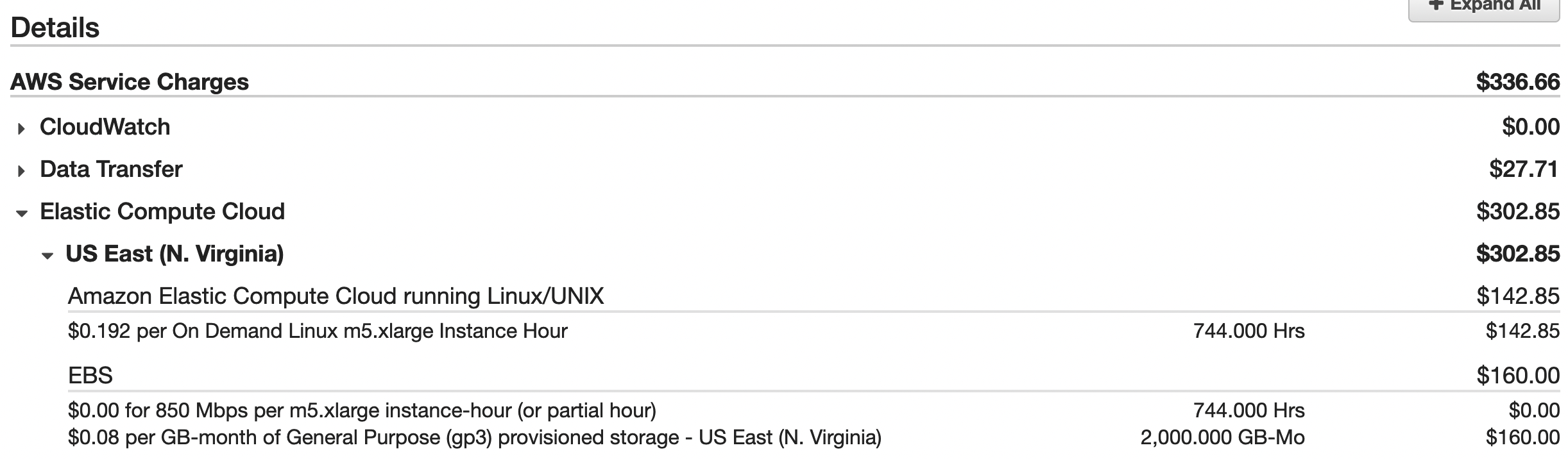
Clearly unsustainable. The expected income for a solo staker is ~0.003 ETH per day. This translates to ~$12-$15 / month at the current ETH prices. I’m not in this for the money, but I’m not willing to lose hundreds of dollars a month to AWS.
Home? Sweet Home.
I ended up re-purposing an Intel
NUC desktop
I wasn’t really using. I reformatted its 2TB SSD, installed a fresh Ubuntu on
it, and ran geth + prysm on it.
In less than 72hrs I was caught up to the chain tip. I haven’t suffered from reliability issues since.
One thing to note if you’re trying to sync from scratch: use Checkpoint Sync
(provider list
here) to let geth
sync without waiting on your beacon node. Concretely, add the following to your
beacon node start command:
--checkpoint-sync-url=https://sync-mainnet.beaconcha.in (or any other Checkpoint Sync provider you trust)
Looking forward
I’m quite happy to have my ETH validator humming along next to me, with no reliance on AWS or my former VPS provider. We’ll see how reliable this setup is long-term.
Going through this made me realize that being offline as a validator isn’t that costly. ETH staking was engineered with solo stakers in mind. The penalty for missing an attestation has the same amount than the reward for successfully attesting.
After doing some more research it seems possible to run an EL+CL combo on cheap hardware. This is what AllNodes claim. I’m also interested to see what Unpool.fi does: as a solo staker, I’d love to use their upcoming EL+CL API as a crutch when I perform maintenance on my own node.
Thanks for reading, and good luck out there!